Anbei ist eine kleine Ansammlung häufiger Fragen, die ich mit dieser FAQ nicht mehr ständig beantworten muss 😉
Wer alle Fehlermeldungen der Search Console sucht, findet sie übrigens hier.
Übersicht aller Fragen:
- Nutzt meine Website das HTTP/2 Protokoll?
- Wie richte ich die Search Console ein?
- Wie filtere ich meinen Brand aus der Search Console?
- Ist meine Seite im Google Index?
- Praktische Google-Suchen
- Wie entferne ich Seiten aus dem Google Index?
- Alle Search Console Fehler – Indexierung
Nutzt meine Website das HTTP/2 Protokoll?
HTTP/2 ist der Nachfolger von HTTP/1.1 und unterstützt das parallele Laden von mehreren Ressourcen (TCP Requests).
Es hat keinerlei Nachteile und sollte ,,einfach“ aktiviert werden (unterstützt der Browser das Protokoll nicht, gibt es einen Fallback auf HTTP/1.1).
Protokolle im Chrome Browser prüfen
- Öffnet dafür im Chrome die Entwicklertools mit F12 oder klickt irgendwo rechts und wählt Element untersuchen aus.
- Wechselt zu Network, refresht die Seite einmal, dann solltet ihr eine tabellarische Ansicht aller Requests sehen.
- Wenn dort nicht bereits eine Protocol Spalte zu sehen ist, klickt rechts auf einen Spaltenheader und wählt es dort aus. Voila.
Beachtet dabei, dass dort auch externe Requests aufgelistet sind, auf dessen Protokoll ihr keinen Einfluß habt (meist sind es aber Cloud Requests, die ein noch neueres HTTP/3 Protokoll nutzen).
Wie richte ich die Search Console ein?
Den Lobgesang auf die Search Console (ehemals Webmastertools) spar ich mir hier, das Tool ist unentbehrlich. Punkt.
Search Console per DNS einrichten
Die ,,technischste“, aber auf lange Sicht komfortabelste Lösung ist es, die ganze Domain als Property über einen DNS Eintrag zu bestätigen. Voraussetzung dafür ist, dass ihr die DNS Konfiguration eurer Domain bearbeiten könnt.
Dafür fügt ihr unter https://search.google.com/search-console eine Property hinzu und gebt unter ,,Domain“ nur den Domainnamen ein (bsp. zerofy.de ohne http oder www).
Kopiert den Eintrag unter Punkt 3 und wechselt zu den DNS Einstellungen eures Hosters. Erstellt einen neuen Eintrag (Record) vom Typ TXT, tragt euren Domainnamen unter Host und den kopierten Wert als Ziel/Value/Wert ein.
Speichern, etwas warten, profit (kann schon einige Stunden dauern).
Search Console per HTML Datei, Meta-Tag bestätigen
Habt ihr keine Möglichkeit, den DNS Eintrag zu setzen, könnt ihr eine der zwei Methoden nutzen. Dann jedoch nur für einen URL Präfix (z.B. die https + www Kombination).
Je nach CMS könnt ihr das Meta-Tag (gehört in den ) in irgendwelchen Settings/Plugins eintragen oder wenn ihr sowieso FTP Zugriff habt, ladet einfach die HTML Datei, die Google euch gibt, in das Hauptverzeichnis. Auf Bestätigen klicken, fertig.
Das könnt ihr nun für alle anderen URL-Präfix Kombinationen sowie Subdomains wiederholen (z.B. http + www). Auch wenn ihr denkt, dass ihr saubere Weiterleitungen habt, ist es durchaus praktisch zu sehen, wie und ob Google andere Präfixe crawlt.
Ist meine Seite im Google Index?
Eine der häufigsten Fragen ist, wie man prüfen kann, ob eine (Unter)seite bei Google indexiert ist oder nicht. Berechtigt, vor allem wenn es eine Kerndienstleistung oder ein Bestseller Produkt ist.
Der site: Operator
Klingt simpel, ist es auch. Einfach nach ,,site:domain.de“ googlen, dann spuckt Google euch die indexierten URLs aus. Bei Seiten mit mehreren tausend URLs wird’s jedoch etwas schwammig und die Ergebnisanzahl ist eher approximiert.
Der inurl: Operator
Mit dieser Suche kann man nach expliziten URL Bestandteilen suchen. Soll also beispielweise das Wort thread (für Foreneinträge) in der URL vorkommen, sucht man nach inurl:thread.
Typische Suchen, die man kennen sollte:
- site:domain.de
listet alle indexierten URLs der Domain domain.de auf (grobe Schätzung bei großen Seiten) - site:domain.de/leistungen
listet alle indexierten URLs auf, die in dem Verzeichnis /leistungen liegen - site:domain.de -inurl:https
findet indexierte http URLs (weil https per – Operator aus URL ausgeschlossen worden ist) - site:domain.de -inurl:www
findet alle URLs ohne www (und Subdomains) - site:domain.de inurl:www
findet alle URLs mit www - site:domain.de -inurl:https
findet unsichere http-Seiten - site:domain.de filetype:php
findet php Dateien (funktioniert natürlich auch für .html, .pdf etc.)
Wie kann ich meine Seite indexieren lassen?
Ist eure Seite auch nach Einrichtung der Search Console nicht via site:domain.de auffindbar, kann es folgende Gründe dafür geben:
Die Seite ist noch zu frisch
Googles Kapazitäten sind, so absurd es klingen mag, auch begrenzt. Entsprechend wird nicht jede Seite mit 2 Besuchern täglich 300 mal gecrawlt. Sehr neue Seiten erhalten geringeres Crawl Budget, sollten aber innerhalb von 2-3 Tagen im Index erscheinen.
Die Seite ist ein technischer Müllhaufen
Bereitet deine Seite dem Crawler Kopfschmerzen, verweigert dieser gerne auch seinen Dienst. Die beliebtesten technischen Probleme sind:
- So lange Ladezeiten, dass der Crawler einen Timeout bekommt und abbricht
- Wenn die robots.txt einen 500er Error wirft
- 301 Redirect Loops (,,Die Seite hat zu oft weitergeleitet“)
Spam, Spam, Spam
Google wird mit der Interpretation von Spam Inhalten immer besser (Stichwörter hier wären E-A-T und YMYL). Sieht Google, dass eure Inhalte Duplikate sind (z.B. von Seiten mit mehr Trust geklaut/gespinnt) oder eure Seite mit Ads- & Pop-Up verseucht (eine normale Nutzung von Ads & Pop-Ups stellt kein Problem dar) ist, werdet ihr eine schwierigere Zeit haben.
Seiten manuell in der Search Console indexieren lassen
Gebt die gewünschte URL einfach in das obere Prüffeld ein. Die Search Console spuckt euch dann Informationen zur aktuellen Indexierung (Indexierungsstatus, Auszeichnungen und Probleme) der jeweligen Unterseite aus. Mit dem ,,Live URL testen“-Button könnt ihr euch die Seite rendern und den HTML Code sowie die Response Requests anzeigen lassen.
Der magische secondary Button ,,Indexierung beantragen“ stößt dann den Indexierungsprozess an. Bei größeren Seiten geht das in Minuten, kleine müssen teilweise ein paar Tage warten.
Wie filtere ich meinen Brand aus der Search Console?
Eine pure SEO Perfomance wird oft fälschlicherweise mit einem Sichtbarbeitsindex oder simplen Klicks aus der Search Console reported. Wenn eure Klicks durch die Decke gehen kann das auch an guter PR liegen.
Um einen groben Überblick zu erhalten, wie ihr ohne Brand Keywords performt, filtert diese erst einmal aus dem Leistungsbericht.
Regex Filter in der Search Console anlegen um Brand Traffic auszuschließen
Geht zu eurem Leistungsbericht (Leistung / Google Suche Ergebnisse), erstellt einen neuen Suchanfragen-Filter (+ Neu) und wählt Regex + ,,Stimmt nicht mit dem Regex überein“.
Hier könnt ihr eure Brandvariationen eintragen. Bei Google wäre es z.B. „(google|googel|gugl|gugel)“. Umgekehrt könnt ihr so natürlich auch nach der Brand Performance filtern.
Wie entferne ich Seiten aus dem Google Index?
Eure Gewinnspielbestätigungsseite liegt schon wieder im Index und rankt besser als eure Landing Page? Eure Möglichkeiten:
Seite aus dem Google Index entfernen mittels Search Console
In der Search Console gibt es den praktischen Menülink Entfernen, der euer Problem dauerhaft lösen könnte. Leider / zum Glück (je nach dem) ist der Antrag, den man dort einreicht aber auf ca. 6 Monate begrenzt. D.h. dass eure Bestätigungsseite in 6 Monaten wieder im Index auftauchen könnte.
Um das wirklich dauerhaft zu verhindern, solltet ihr die nächsten zwei Maßnahmen beherzigen:
Seite per Robots-Meta-Tag auf noindex stellen
Wenn man dem Google Crawler nicht explizit sagt, dass eine bestimmte Seite von der Indexierung ausgeschlossen sein soll, wird Google die Seite meist automatisch indexieren. Die praktischste Anweisung dabei ist das Robots-Meta-Tag im <head>.
<meta name="robots" content="noindex">Dieses Meta-Tag sagt allen Crawlern (Robots), dass die Unterseite nicht indexiert werden soll. Die meisten CMS erlauben es einem mittels Plugin die ,,SEO Einstellungen“ (o.Ä.) zu bearbeiten.
Crawling der Seite per robots.txt blockieren
Fälschlicherweise wird das Blockieren einer Seite in der robots.txt oft als Standalone Lösung angepriesen. Setzt man jedoch kein zusätzliches noindex Meta-Tag, kann der Index trotzdem zugemüllt werden. Dazu sehen die Ergebnisseiten auch noch richtig scheiße aus, da Google die restlichen Meta-Informationen nicht ziehen kann.
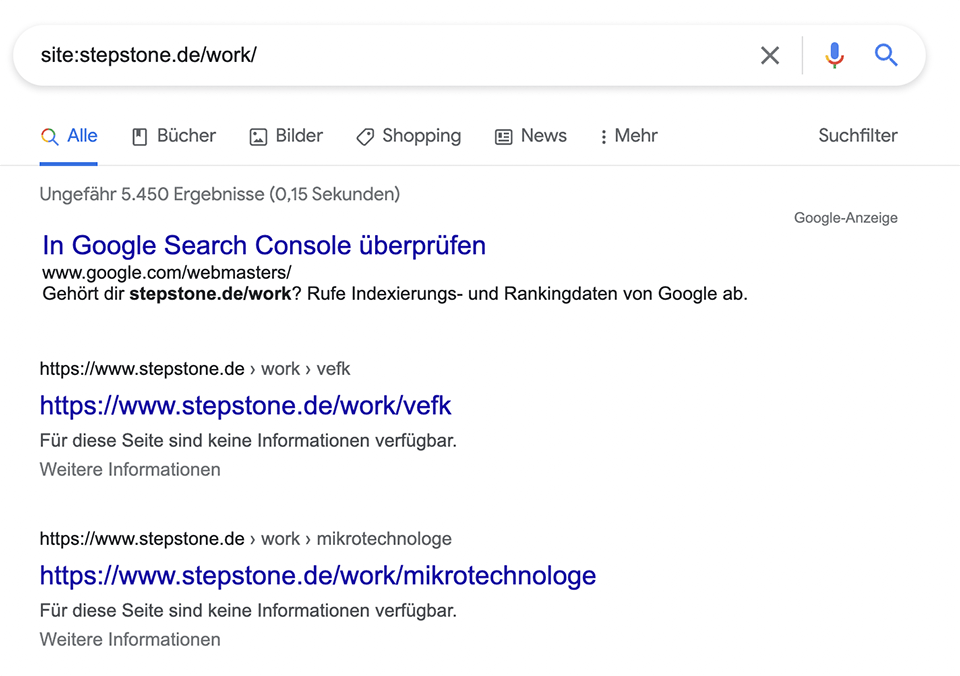
In diesem Beispiel ist zwar ein noindex Tag gesetzt, ich vermute jedoch, dass die URLs erst per robots.txt blockiert wurden, als 5000 Seiten ohnehin schon im Index lagen.
Seht also zu, dass ihr erst blockiert, wenn die Seiten bereits deindexiert sind.
