Enclosed is a small collection of common questions that I no longer have to answer constantly with this FAQ 😉
Overview of all questions:
- Does my website use the HTTP/2 protocol?
- How do I set up Search Console?
- How do I filter my brand from Search Console?
- Is my page in the Google index?
- Practical Google searches
- How do I remove pages from the Google index?
Does my website use the HTTP/2 protocol?
HTTP/2 is the successor of HTTP/1.1 and supports parallel loading of multiple resources (TCP requests).
It has no disadvantages and should be "simply" enabled (if the browser does not support the protocol, there is a fallback to HTTP/1.1).
Check logs in Chrome browser
- To do this, open the developer tools in Chrome with F12 or click somewhere on the right and select Examine Element.
- Switch to Network, refresh the page once, and you should see a tabular view of all requests.
- If there is not already a Protocol column there, right click on a column header and select it there. Voila.
Note that there are also external requests listed whose protocol you have no influence on (but mostly they are cloud requests that use an even newer HTTP/3 protocol).
How do I set up Search Console?
I won't sing the praises of Search Console (formerly Webmaster Tools) here, the tool is indispensable. Point.
Set up Search Console via DNS
The most "technical", but in the long run the most comfortable solution is to confirm the whole domain as a property via a DNS entry. The prerequisite for this is that you can edit the DNS configuration of your domain.
To do this, add a property at https://search.google.com/search-console and enter only the domain name under "Domain" (e.g. zerofy.de without http or www).
Copy the entry under point 3 and change to the DNS settings of your hoster. Create a new record of type TXT, enter your domain name under Host and the copied value as Target/Value/Value.
Save, wait a little, profit (can already take a few hours).
Confirm Search Console via HTML file, meta tag
If you have no possibility to set the DNS entry, you can use one of the two methods. But then only for one URL prefix (e.g. the https + www combination).
Depending on your CMS you can add the meta tag (belongs in the ) in any settings/plugins or if you have FTP access anyway, just load the HTML file Google gives you into the root directory. Click on confirm, done.
You can now repeat this for all other URL prefix combinations and subdomains (e.g. http + www). Even if you think you have clean redirects, it is quite handy to see how and if Google crawls other prefixes.
Is my page in the Google index?
One of the most common questions is how to check if a (sub)page is indexed on Google or not. Justified, especially if it is a core service or a best-selling product.
The site: Operator
Sounds simple, it is. Just google for "site:domain.de", then Google spits out the indexed URLs. For pages with several thousand URLs, however, it becomes a bit spongy and the number of results is rather approximate.
The inurl: operator
With this search you can search for explicit URL components. For example, if you want the word thread (for forum entries) to appear in the URL, search for inurl:thread.
Typical searches you should know:
- site:domain.de
lists all indexed URLs of the domain domain.de (rough estimate for large sites) - site:domain.de/services
lists all indexed URLs that are located in the directory /services - site:domain.de -inurl:https
finds indexed http URLs (because https has been excluded from URL by - operator) - site:domain.de -inurl:www
finds all URLs without www (and subdomains) - site:domain.de inurl:www
finds all URLs with www - site:domain.de -inurl:https
finds insecure http pages - site:domain.de filetype:php
finds php files (of course also works for .html, .pdf etc.)
How can I get my site indexed?
If your site is not discoverable via site:domain.de even after setting up Search Console, there may be the following reasons:
The page is still too fresh
Google's capacities are, as absurd as it may sound, also limited. Accordingly, not every page with 2 visitors is crawled 300 times a day. Very new pages receive lower crawl budget, but should appear in the index within 2-3 days.
The site is a technical garbage heap
If your site gives the crawler a headache, it also likes to refuse its service. The most popular technical problems are:
- Loading times so long that the crawler gets a timeout and aborts
- If the robots.txt throws a 500 error
- 301 Redirect Loops (,,The page has redirected too often")
Spam, spam, spam
Google is getting better at interpreting spam content (keywords here would be E-A-T and YMYL). If Google sees that your content is duplicate (e.g. stolen/pinned from pages with more trust) or your page is infested with ads & pop-ups (a normal use of ads & pop-ups is not a problem), you will have a more difficult time.
Have pages indexed manually in Search Console
Simply enter the desired URL in the upper check box. The Search Console then spits out information about the current indexing (indexing status, awards and problems) of the respective subpage. With the "Test Live URL" button you can render the page and display the HTML code and the response requests.
The magic secondary button "Request indexing" then triggers the indexing process. For larger sites this takes minutes, smaller ones sometimes have to wait a few days.
How do I filter my brand from Search Console?
A pure SEO performance is often falsely reported with a visibility index or simple clicks from Search Console. If your clicks go through the roof, it can also be due to good PR.
To get a rough overview of how you perform without brand keywords, filter them out of the performance report first.
Create regex filter in Search Console to exclude brand traffic
Go to your performance report (Performance / Google Search Results), create a new search query filter (+ New) and select Regex + ,,Does not match regex".
Here you can enter your brand variations. For Google, for example, it would be "(google|googel|gugl|gugel)". Conversely, you can of course also filter by brand performance.
How do I remove pages from the Google index?
Your sweepstakes confirmation page is already back in the index and ranking better than your landing page? Your options:
Remove page from Google index using Search Console
In Search Console there is the handy Remove menu link that could solve your problem permanently. Unfortunately / fortunately (depending on the) the request you submit there is limited to about 6 months though. I.e. your confirmation page could reappear in the index in 6 months.
To really prevent this permanently, you should take the next two measures to heart:
Set page to noindex via robots meta tag
Wenn man dem Google Crawler nicht explizit sagt, dass eine bestimmte Seite von der Indexierung ausgeschlossen sein soll, wird Google die Seite meist automatisch indexieren. Die praktischste Anweisung dabei ist das Robots-Meta-Tag im <head>.
<meta name="robots" content="noindex">This meta tag tells all crawlers (robots) that the subpage should not be indexed. Most CMS allow you to edit the "SEO settings" (or similar) using a plugin.
Block crawling of the page via robots.txt
Incorrectly, blocking a page in robots.txt is often touted as a standalone solution. However, if you do not set an additional noindex meta tag, the index can still be cluttered. In addition, the result pages look really crappy, because Google can not pull the rest of the meta information.
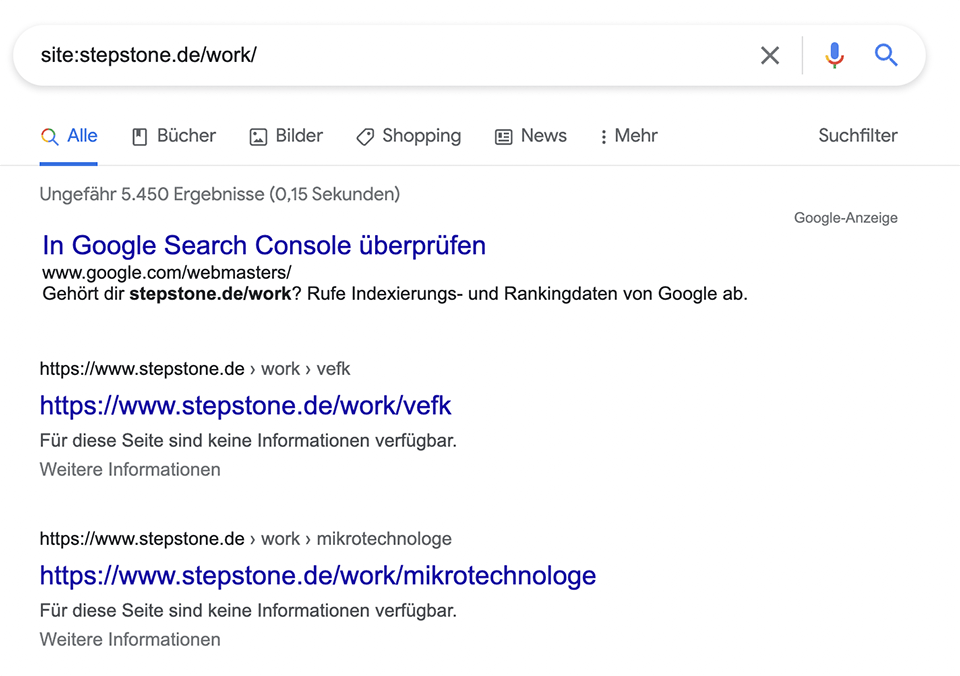
In this example, a noindex tag is set, but I suspect that the URLs were only blocked via robots.txt when 5000 pages were already in the index anyway.
So make sure that you block only after the pages are already deindexed.